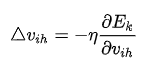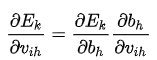X = array([[1, 0], [0, 1], [0, 0], [1, 1]])
y = array([[1], [1], [0], [0]])
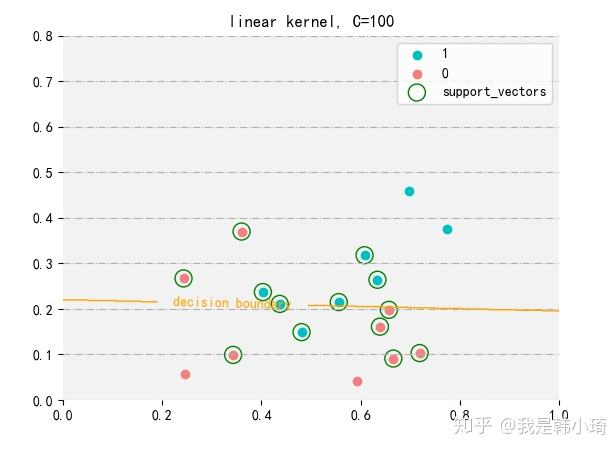
간단한 데이터 세트를 사용해 RBF신경망을 훈련해 봅시다.
여기서는 평균제곱오차를 손실함수로 사용합니다. 출력층은 책과 동일하고, 은닉층의 선형조합을 위해 바이어스항을 추가했습니다.
import numpy as np
import matplotlib.pyplot as plt
def RBF_forward(X_, parameters_):
m, n = X_.shape
beta = parameters_['beta']
W = parameters_['W']
c = parameters_['c']
b = parameters_['b']
t_ = c.shape[0]
p = np.zeros((m, t_)) # 식5.19
x_c = np.zeros((m, t_)) # 5.19식에서 x - c_{i} 부분
for i in range(t_):
x_c[:, i] = np.linalg.norm(X_ - c[[i],], axis=1) ** 2
p[:, i] = np.exp(-beta[0, i] * x_c[:, i])
a = np.dot(p, W.T) + b
return a, p, x_c
def RBF_backward(a_, y_, x_c, p_, parameters_):
m, n = a_.shape
grad = {}
beta = parameters_['beta']
W = parameters_['W']
da = (a_ - y_)
dw = np.dot(da.T, p_) / m
db = np.sum(da, axis=0, keepdims=True) / m
dp = np.dot(da, W)
dbeta = np.sum(dp * p_ * (-x_c), axis=0, keepdims=True) / m
assert dbeta.shape == beta.shape
assert dw.shape == W.shape
grad['dw'] = dw
grad['dbeta'] = dbeta
grad['db'] = db
return grad
def compute_cost(y_hat_, y_):
m = y_.shape[0]
loss = np.sum((y_hat_ - y) ** 2) / (2 * m)
return np.squeeze(loss)
def RBF_model(X_, y_, learning_rate, num_epochs, t):
'''
:param X_:
:param y_:
:param learning_rate:
:param num_epochs:
:param t:
:return:
'''
parameters = {}
np.random.seed(16)
parameters['beta'] = np.random.randn(1, t)
parameters['W'] = np.zeros((1, t)) # 초기화
parameters['c'] = np.random.rand(t, 2)
parameters['b'] = np.zeros([1, 1])
costs = []
for i in range(num_epochs):
a, p, x_c = RBF_forward(X_, parameters)
cost = compute_cost(a, y_)
costs.append(cost)
grad = RBF_backward(a, y_, x_c, p, parameters)
parameters['beta'] -= learning_rate * grad['dbeta']
parameters['W'] -= learning_rate * grad['dw']
parameters['b'] -= learning_rate * grad['db']
return parameters, costs
def predict(X_, parameters_):
a, p, x_c = RBF_forward(X_, parameters_)
return a
X = np.array([[1, 0], [0, 1], [0, 0], [1, 1]])
y = np.array([[1], [1], [0], [0]])
#
parameters, costs = RBF_model(X, y, 0.003, 10000, 8)
plt.plot(costs)
plt.show()
print(predict(X, parameters))
# 검정
# parameters = {}
# parameters['beta'] = np.random.randn(1, 2) # 初始化径向基的方差
# parameters['W'] = np.random.randn(1, 2) # 初始化
# parameters['c'] = np.array([[0.1, 0.1], [0.8, 0.8]])
# parameters['b'] = np.zeros([1, 1])
# a, p, x_c = RBF_forward(X, parameters)
#
# cost = compute_cost(a, y)
# grad = RBF_backward(a, y, x_c, p, parameters)
#
#
# parameters['b'][0, 0] += 1e-6
#
# a1, p1, x_c1 = RBF_forward(X, parameters)
# cost1 = compute_cost(a1, y)
# print(grad['db'])
#
# print((cost1 - cost) / 1e-6)code출처:https://github.com/han1057578619/MachineLearning_Zhouzhihua_ProblemSets/blob/master/ch5--%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C/5.7/RBF.py