이 컬럼이 나온 시기가 2012년인데, 10년이 흐른 지금 컬럼의 저자인 Thomas H.Davenport 와 DJ Patil가 하버드 비즈니스 리뷰에 <데이터 사이언티스트는 여전히 21세기 가장 섹시한 직업인가? Is Data Scientist Still the Sexiest Job of the 21st Century?>라는 컬럼을 기고했다.
-지금은 은행, 보험회사, 유통회사 뿐만 아니라 정부 기관에도 데이터 사이언스 조직이 있다.
-원인은 양질의 데이터 사이언스 교육이 증가했기 때문.
주관적인 생각을 더해 정리하자면, 데이터 사이언티스트가 인공지능 관련 필드에서만 활약하는 것이 아닌, IT기업부터 일반 제조, 그리고 정부까지 곳곳에 침투해 많은 역할을 하고 있다는 것이다. 실제로 링크드인에 ‘데이터 사이언티스트’라고 검색만 해봐도 정말 다양한 기관과 회사에서 데이터 사이언티스트를 채용하는 것을 확인할 수 있다. 특히 최근 2-4년 사이에 엄청난 붐이었다. 지금도 물론 많이 뽑고 있지만, 아래 설명할 내용처럼 그 직업의 범위가 재정의되고 있는 중이다.
2) 재정의되는 데이터 사이언티스트의 역할 (Data Scientists in Relation to Other Roles)
-데이터 사이언티스트가 다른 많은 역할을 할것이라고 예상했지만, 현실은 데이터 사이언스와 관련된 많은 다른 역할들이 생겼고, 어떤 것들은 데이터 사이언스보다 인기가 높음. (ex. 데이터 엔지니어, data product manager 등)
-늘어나는 데이터 양과 복잡해지는 시스템
-모델을 만들어서 deploy하는 경우가 많이 없음, 아직 실무에서 AI를 적용하기에 용이한 곳이 많지 않다. (즉 역할이 더 분화되고 세분화된 역할을 잘하는 인재들이 많아져야 한다)
개인적인 생각으로는 2012년의 데이터 사이언티스트는 지금의 ML or DL research scientist (리서치 사이언티스트)에 가까운 것 같다.
개인적으로는 다음과 같이 분류해야 한다고 생각한다.
[1] 머신러닝 or 딥러닝 리서치 사이언티스트
알고리즘 연구에 초점을 맞춘 데이터 사이언티스트라고 할 수 있겠다. 그리고 리서치 사이언티스트는 컴퓨터 비전, NLP 등 전문 분야의 연구원으로 분류되고 있는 추세다.
[2] Applied data scientist (데이터 사이언티스트)
1번과 비슷하지만 보다 더 비즈니스적이고 practical한 부분에 초점을 맞추고 있는 데이터 사이언티스트이며, 앞으로는 이러한 부류가 흔히 말하는 ‘데이터 사이언티스트’로 정의되지 않을까 싶다.
Applied data scientist 라는 용어는 한 2년전부터 보이기 시작했고, 업계에서 완전히 통용되는 용어는 아니나, 1번과 구별하기 위해서 사용하기 좋은 것 같다.
Meta의 데이터사이언티스트인 Deepak Chopra는 그의 블로그에서 applied data scientist 에 대해 다음과 같이 정의하고 있다.
Applied data scientist는 간단히 말해, 비즈니스에 적용할 수 있는 솔루션을 제공할 목적으로 이론적 개념 프레임워크와 알고리즘을 데이터에 적용하며 데이터(즉, 데이터 과학)에 대해 공부하는 사람(
An Applied Data Scientist, simply put, is someone who studies the data (i.e. data science) with the aim of providing actionable solutions to business problems by applying theoretical conceptual frameworks and algorithms on the underlying data.) 그리고 비즈니스 문제를 풀기 위해 데이터를 정제하고, 분석하고, 모델링해 의미있는 인사이트를 도출하는 사람 (Someone who processes, analyzes, models and interprets data of any kind to drive meaningful insights and help solve business problem)이라고 정의한다.
여기서 중요한 것은 정제, 분석, 모델링이다. 즉…데이터 정제 뿐만 아니라 분석, 모델링까지 모두 할 줄 알아야한다. 여기서 많이 오해하는 부분이 ‘정제(process)’인데, 단순히 준비된 데이터를 pre-processing하는 과정만 말하는 것이 아니라, 간단한 데이터 파이프라인 설계부터 해서 원천 데이터(raw data)를 자유자재로 가공해 원하는 분석환경으로 이동시킬 수 있어야 한다. 사실 회사마다 분석환경도 다르고 데이터 저장 아키텍처가 다르기 때문에, 경험이 적은 주니어일수록 이 부분에 약한 것이 사실이다. 따라서 이 부분을 채우려면 실무자 강의를 듣거나 기존에 블로그에 올렸던 강의를 들어보길 추천한다.
데이터 엔지니어의 역할도 굉장히 동적으로 변화하고 있다. 그 이유는 아래서 나오는 요인인 ‘chages in technology’ 현상과 연관이 깊다. 데이터 양도 많아지고, 비즈니스가 복잡해지면서 만든 모델을 관리하거나 데이터 파이프라인을 잘 관리할 수 있는 역할이 필요해졌다. 특히 큰 기업같은 경우는 데이터 보안 문제도 매우 중요하기 때문에 아키텍처 설계부터 보안관리까지 전문영역이 늘어나고 있다.
MLOps라는 직무가 새롭게 뜨고 있는 것만 봐도 그렇다. 지금까지의 데이터 엔지니어의 역할은 데이터 파이프라인을 잘 설계해 분석을 쉽게 만들어주는 것이었다면, 클라우드 리소스 관리, 데이터 정합성 관리, ML 모델 배포 및 관리 등 계속해서 확장되고 세분화 될 것이다.
사실 이러한 작업이 잘 되는 조직의 데이터 분석 및 활용 능력이 높아지기 때문에, 기업들은 많은 시행착오를 거쳐 지금은 매우 중요한 역할임을 인식하게 되었고, 현재 수요가 가장 많은 직군이 아닌가 생각한다. 컬럼에서도 밝혔듯이 오히려 데이터 사이언티스트보다 인기가 높다.
[4] 데이터 분석가 (or 비즈니스 분석가)
Data Analyst와 Business Analyst를 혼용하는 곳이 많은데, 사실 나는 같은 의미라고 생각한다. 기업에서 데이터 분석을 왜 하는가? 비즈니스를 위해서다. 다만 최근에는 ‘무엇을 분석하는가’에 대한 부분이 전문화되고 세분화되고 있다. 대표적인 것이 HR data analyst 일 것이다. Human resource 부서의 데이터만 전문적으로 분석하는 직종인데, 대이직 시대가 되고 재택근무가 활성화되면서 각광받고 있다.
가장 궁금해할 부분은 ‘데이터 분석가’와 ‘데이터 사이언티스트’의 차이인데, 현실적으로 많은 기업에서 데이터 분석가의 업무는 sql을 활용한 쿼리 추출 및 지표 관리가 주를 차지한다. 데이터 사이언티스트도 분석을하고 sql을 사용한다. 하지만 대부분 모델링 기반 새로운 프로덕트 생성을 위한 데이터 분석을 진행하거나, ML이나 DL 기반의 프로젝트를 만들기 위해 과제 발굴 작업 단계에서의 데이터 분석을 많이 진행한다. 반면 데이터 분석가 혹은 비즈니스 분석가는 daily로 봐야하는 지표나 전사에 공유되야 하는 중요한 비즈니스 지표들을 발굴하고 모니터링하는 작업을 많이 한다.
이제 다시 컬럼으로 돌아가 세 번째 변화를 살펴보자.
3) 기술의 변화 (changes in technology)
AutoML같은 기술로 인해 많은 부분이 자동화 됨.
그로 인해 회사들은 ‘시티즌 데이터 사이언티스트’를 키우려는 추세
-비즈니스 환경이 달라져서 배치한 모델을 계속해서 모니터링할 필요성을 느낌. MLOps가 뜬 이유.
-2012년에 비해 coding 스킬이 중요하지 않아졌다 → 좋은 package, library로 인해 하드코딩 작업의 필요성이 줄어듬
너무나도 당연하지만 AI기술, 그리고 AI를 지탱하는 많은 인프라 기술들이 큰 발전을 거듭했다. 위에서 언급한 것처럼 데이터 엔지니어의 중요성이 커지고 있으며 데이터 엔지니어라는 직무 또한 계속해서 세분화되고 있다. 코딩이 필요없어질만큼 많은 부분이 자동화되고 있으며, 이에 따라 데이터 과학 지식을 겸비한 일반 ‘시티즌 데이터 사이언티스트’ 를 양성하고자 하는 움직임도 보인다.
사실 아직 coding이 필요없어질 정도는 아니지만, 비즈니스에 ML을 적용하며 생각할 수 있는 기능 대부분은 이미 라이브러리화 되어 제공되고 있는 것이 사실이다. 특히 클라우드 사업자들은 경쟁에서 이기기 위해 더 편하고 좋은 기능을 내놓으려 혈안이 되어 있고, 이에 따라 소비자들은 AI를 비즈니스에 적용하는 허들이 계속해서 낮아지는 것을 목격할 수 밖에 없다.
4) 데이터 과학의 윤리(The Ethics of Data Science)
첫 컬럼을 쓸때와 가장 달라진 부분은 바로 데이터 과학에 대한 윤리 문제가 부각되고 있다는 점이다. 책임감 있는 AI, 데이터 투명화 등의 주제가 큰 이슈로 떠올랐는데, 따라서 테크가 아닌 non-tech분야, 즉 법률이나 윤리 부분의 전문가들의 중요성이 커지는 추세라고 한다.
다시 한 번 결론이다.
결론. 데이터 사이언티스트라는 직업은 크고 작게 변화하고 있다.
제도화 (institutionalized, 혹은 일상화라고 번역하고 싶다) 되고 있고;
데이터 사이언티스트라는 직업의 범위(scope)이 재정의 되고 있으며;
데이터 사이언스를 둘러싼 기술들에 많은 변화가 생겼으며;
관련된 non-tech 전문가들의 중요성이 커지고 있다.
데이터 사이언티스트는 여전히 가장 섹시한 직업인가?
사실 컬럼 제목에 대한 직접적인 답은 내용에 없다. 그들의 처음 주장하던 시기와 비슷한 부분도 있고 변화한 부분도 있다고 주장하고 있을 뿐이다. 애초에 'sexy'라는 단어에 포커스를 둔 컬럼이 아니었는데, 데이터와 AI에 대한 관심때문에 많이 인용되다보니 내용보다는 sexy라는 단어에 초점이 맞춰져있던 것같다...
sexy라는 개념이 아무래도 주관적인 것이니 정답은 없을 것이다...
개인적으로는 sexy는 모르겠고 가장 유망한 직업 중 하나이며, 계속해서 동적으로 그 역할(role) 자체가 세분화되고 변화하는 직업이라고 생각한다.
나도 몰라서 고생했던 부분이 많은데, 특히 command shell, version control(Git), remote machine 등에 대한 내용은 모델을 배포할 때, 처음에 시스템을 설정할 때 등 유용하게 쓰이는 테크닉들이다.
아무래도 CS전공이 아닌 데이터 사이언티스트나 분석가 분들이 많이 찾는 내용이 가득할 것이다.
--- 수업 동기:
왜 우리가 이 수업을 가르칠까요?
전통적인 컴퓨터 과학(CS) 교육을 듣는 동안 운영 체제, 프로그래밍 언어, 기계학습에 이르기까지 CS 내의 고급 주제들을 가르치는 많은 수업을 듣게 될 것입니다. 그러나 많은 기관에서는 거의 다루지 않고 학생들이 스스로 학습할 수 있도록 남겨진 필수적인 한 가지 주제가 있는데 바로 컴퓨터 생태계 활용 능력입니다.
지난 수 년간, 우리는 MIT에서 몇 가지 수업을 하는 것을 도왔고, 계속해서 많은 학생들이 사용하는 툴에 대한 제한된 지식을 가지고 있다는 것을 알았습니다. 컴퓨터는 수동 작업을 자동화하기 위해 만들어졌지만 학생들은 종종 손으로 반복 작업을 수행하거나 version control과 text editor와 같은 강력한 도구를 충분히 활용하지 않았습니다. 최상의 경우, 이는 비효율성과 시간 낭비를 초래하고, 최악의 경우 데이터 손실이나 특정 작업을 완료할 수 없는 등의 문제를 초래합니다.
이러한 주제들은 대학 커리큘럼의 일부로 가르치지 않습니다. 학생들은 이러한 도구들을 어떻게 사용하는지를 결코 알 수 없거나, 적어도 어떻게 효율적으로 사용하는지를 알지 못하며, 따라서간단해야 할과제에 시간과 노력을 낭비합니다. 표준 CS 커리큘럼은 학생들의 삶을 훨씬 더 쉽게 만들 수 있는 컴퓨팅 생태계에 대한 중요한 주제들이 빠져 있습니다.
여러분의 CS 교육에서 누락된 학기
이 문제를 해결하기 위해 우리는 효과적인 컴퓨터 과학자와 프로그래머가 되기 위해 중요하다고 생각하는 모든 주제를 다루는 수업을 운영하고 있습니다. 이 수업은 실제적이고 실용적이며, 여러분이 접하게 될 다양한 상황에서 즉시 적용할 수 있는 툴과 기술에 대한 실습 소개를 제공합니다. 이 수업은 2020년 1월 MIT의 “독립 활동 기간” 동안 운영되고 있는데, 이는 단축 수업을 위한 한 달짜리 학기입니다. 수업 자체는 MIT 학생들만 수강할 있지만 녹화된 수업 영상과 함께 모든 수업 자료를 대중에게 제공할 예정입니다.
만약 이 내용이 여러분에게 해당하는 것처럼 들린다면, 이 수업이 무엇을 가르칠 것인지에 대한 구체적인 예들이 아래에 나와 있습니다:
Command shell
별칭(aliases), 스크립트 및 빌드 시스템을 사용하여 일반 작업과 반복 작업을 자동화하는 방법에 대해 알아봅니다. 일반 문서에서 복사-붙여넣기 명령어를 더 이상 사용하지 않을 겁니다. “이 15개의 명령을 차례로 실행”을 더 이상 하지 않을 겁니다. “이것을 실행하는 방법을 잊었다”거나 “이 argument의 사용법을 잊어버렸다”는 말은 더 이상 하지 않을 겁니다.
예를 들어, 여러분의 shell history를 빠르게 검색하는 것은 엄청난 시간 절약이 될 수 있습니다. 아래와 같이 명령변환을 위한 shell history 탐색과 관련된 몇 가지 트릭을 보여 줍니다.
Version control
Version control을올바르게사용하는 방법과 이를 활용하여 난관에서 여러분을 구하고, 다른 사람들과 협력하며, 문제가 있는 변경사항을 신속하게 찾아 격리하는 방법에 대해 알아봅니다.rm -rf; git clone을 수행하는 일은 더 이상 없을 겁니다. 병합 충돌은 더 이상 없을 겁니다(글쎄요, 최소한 더 적은 수라고 해야겠군요). 주석이 들어간 큰 코드 블록은 더 이상 없을 겁니다. 어떤 요소가 여러분의 코드를 깨트리는지 더 이상 애태우지 마세요. “안돼, 설마 작업 중인 코드를 삭제했나?!” 라고 더 이상 외칠 일이 없습니다. Pull requests로 다른 사람의 프로젝트에 기여하는 방법까지 알려드리겠습니다!
아래와 같이git bisect를 사용하여 어떤 커밋이 unit test를 깨트렸는지 찾은 후에git revert로 수정하는 것입니다.
Text editing
로컬 및 원격으로 command-line에서 파일을 효율적으로 편집하고 고급 편집기 기능을 활용하는 방법에 대해 알아봅니다. 파일을 앞뒤로 복사하는 일은 더 이상 하지 않게 될 겁니다. 반복적인 파일 편집이 더 이상 필요 없게 됩니다.
Vim 매크로는 가장 좋은 기능 중 하나인데, 아래와 같이 html 테이블을 중첩된 vim 매크로를 사용하여 csv 형식으로 빠르게 변환시킬 수 있습니다.
Remote machines
SSH 키 및 터미널 멀티플렉싱을 사용하여 원격 시스템과 작업할 때 정상적으로 유지하는 방법에 대해 알아봅니다. 두 개의 명령을 한 번에 실행하기 위해 많은 터미널을 열어둘 필요가 더 이상 없을 겁니다. 연결할 때마다 더 이상 암호를 입력하지 않아도 됩니다. 인터넷 연결이 끊겼거나 노트북을 재부팅해야 한다고 해서 모든 것을 잃을 일은 더 이상 없을 겁니다.
아래와 같이 세션을 원격 서버에서 활성 상태로 유지하기 위해tmux를 사용하고 네트워크 로밍과 연결을 지원하기 위해mosh를 사용합니다.
Finding files
신속하게 원하는 파일을 찾는 방법에 대해 알아 봅니다. 원하는 코드가 있는 파일을 찾을 때까지 프로젝트의 파일을 클릭하는 일은 더 이상 하지 않아도 됩니다.
아래와 같이fd가 있는 파일과rg가 있는 코드 스니펫을 빠르게 찾아볼 수 있습니다. 또한fasd를 사용하여 최근/자주 사용하는 파일/폴더도cd와vim을 실행할 수 있습니다.
Data wrangling
Command-line에서 직접 데이터 및 파일을 빠르고 쉽게 수정, 보기, 구문 분석, 그래프 그리기 및 계산하는 방법에 대해 알아봅니다. 로그 파일에서 복사, 붙여넣기를 더 이상 하지 않아도 됩니다. 데이터에 대한 통계를 더 이상 수동으로 계산하지 않아도 됩니다. 이제는 스프레드시트에 그래프를 그리지 않아도 됩니다.
Virtual machines
가상 머신을 사용하여 새로운 운영 체제를 시도하고, 관련 없는 프로젝트를 분리하며, 주 머신을 깨끗하고 깔끔하게 유지하는 방법에 대해 알아봅니다. 보안 랩을 수행하는 동안 실수로 컴퓨터를 더 이상 손상시키지 않아도 됩니다. 버전이 다른 수백만 개의 무작위로 설치된 패키지는 더 이상 필요 없습니다.
Security
여러분의 모든 비밀을 세상에 즉시 드러내지 않고 인터넷에 접속하는 방법에 대해 알아봅니다. 너무 취약한 자신의 정보과 일치하는 비밀번호를 더 이상 사용하지 않을 겁니다. 보안되지 않은 개방형 WiFi 네트워크는 더 이상 없을 겁니다. 암호화되지 않은 메시지는 더 이상 없을 겁니다.
Conclusion
위의 내용과 더불어 더 많은 내용이 12개의 수업에서 수업 내용과 함께 연습 문제를 포함되어 있습니다. 1월을 기다릴 수 없다면 지난해 IAP 때 운영했던Hacker Tools강의를 살펴봐도 좋습니다. Hacker Tools는 이 수업의 선구자격로서, 같은 주제를 많이 다루고 있습니다.
실무 경험이 없거나 적은 주니어 데이터 사이언티스트가 가장 많이 궁금해하고 알고 싶어하는 부분은 바로 본인이 한 모델링 결과를 어떻게 비즈니스에 적용하느냐에 대한 것이다.
물론 비즈니스 구조가 다르고, 사용하고 있는 시스템이 다르기 때문에 획일적인 답안이 존재하는 것은 아니지만
이러한 궁금증을 해소시켜줄 강의 자료가 있어 소개한다.
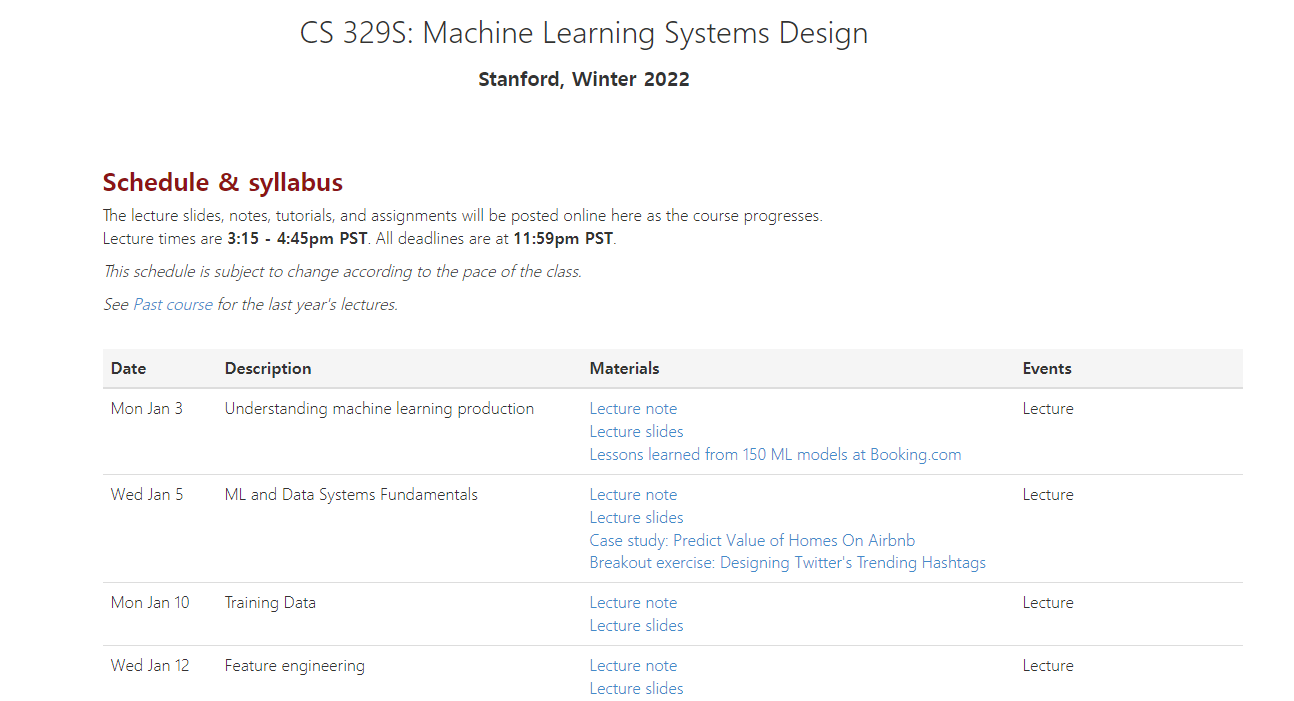
바로 스탠포드 대학의 공개 강의인 CS329s 이다.
Lecture note가 워낙 상세해서, Lecture note와 lecture slides만 봐도 큰 도움이 된다.
그리구 후반부에는 실무자들의 강연이 이어지는데,
실무에서 어떤식으로 모델링된 결과를 적용하고 모니터링하는지 아주 상세히 설명해주고 있다.
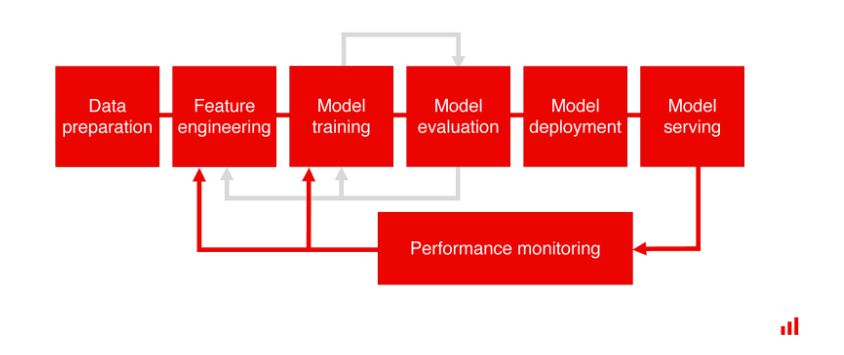
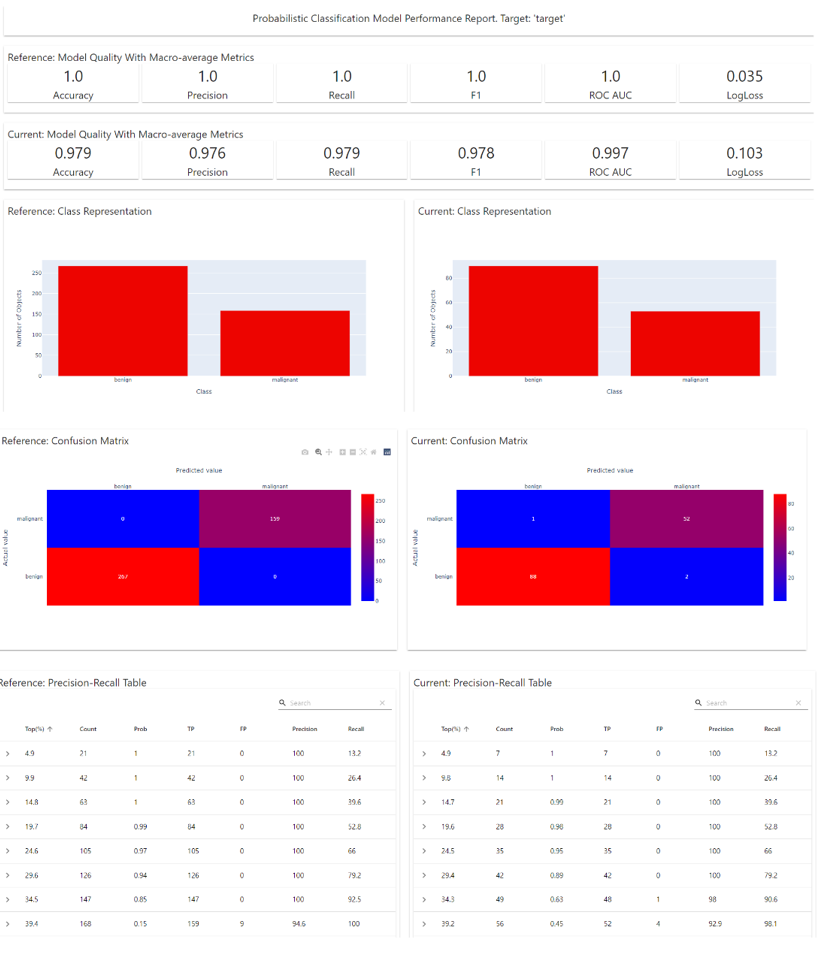
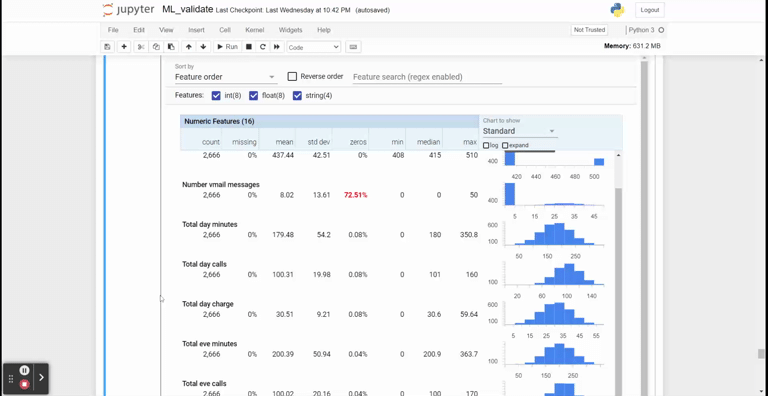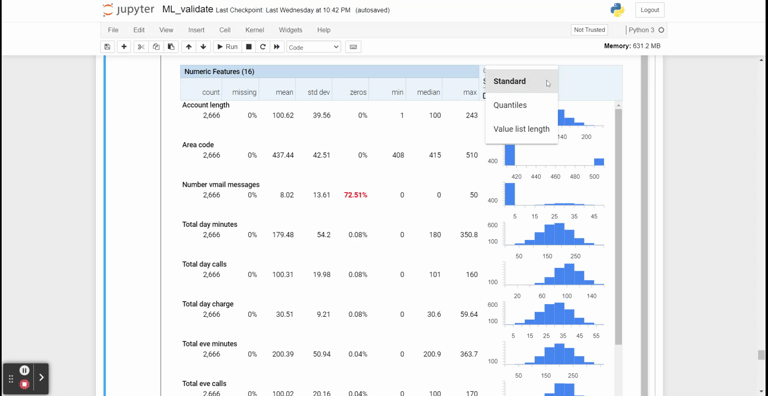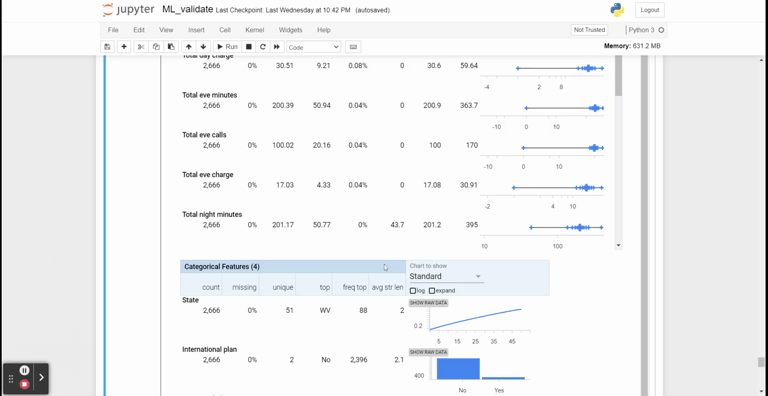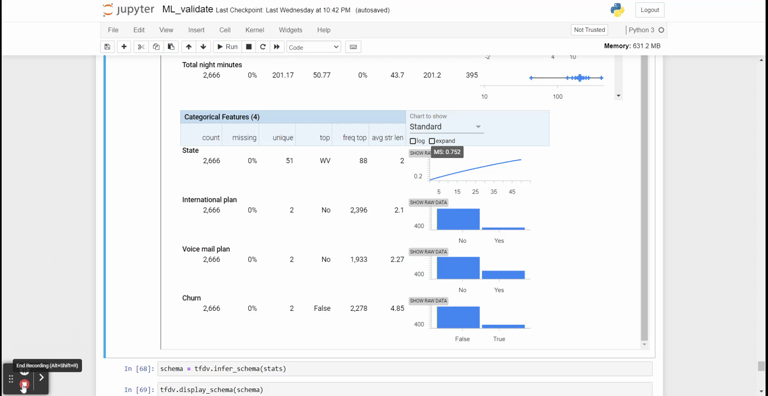
특히 아래와 같이 모니터링 코드 샘플까지 제공하고 있다!
모니터링 샘플 예시 - 실제로 모델링된 결과를 어떻게 활용하는지 보여줌
아마도 부트캠프 같은 곳에서는 실제 모델링한 결과물을 적용하는 실습을 하거나,
직간접적으로라도 경험하기 힘든 부분들이 많은데,
이런 자료를 통해 어느정도 그 니즈를 해소했으면 한다.
개인적으로 데이터 사이언티스트로서 성장하기 위해서는 MLOps라고 부르는 파트의 지식이 쌓여아 한다고 생각한다.
AI research scientist가 아닌 이상, 내가 만든 product를 보다 효율적으로 deploy하고 활용하는 방안을 고민하고, 또 필요한 경우 직접 처리 할 수 있는 skill을 배워야 한다. 이미 이러한 일들이 효과적으로 배분되어 있는 데이터팀이 있는 경우가 아니라면...(혹시 그런 팀에 있다고 하더라고 co-work을 위해^^)